

M5StickCで速読リーダーを作ってみた
こんにちは、Lineaです。
最近は買い物レビュー記事が続いていましたが、久々にプログラミングの記事です。
この前、普段観ているEテレの2355という番組で面白い生理現象?が紹介されていました。
文章の位置が変わらなければ人間は高速に文章が読めるという内容です。文章を読むときには目線を動かして文を追っているのですが、位置が変わらずに文章が切り替わると目線を動かさなくて良いので読めるそうです。Youtubeに同じ効果を紹介した動画がありました。
この効果を知って、本を速読するのに使えるのではと思いました。ちょうどM5StickCだとコンパクトで1行分の文字を表示できるサイズの画面を持ってるので、これで速読リーダーを作ってみたのが今回の内容になります。
青空文庫からダウンロードした本のテキストデータを加工して表示させています。メニュー画面で内部に保存しているテキストファイルを一覧から選択して読むことができます。1行ずつテキスト表示を切り替えていくので動画と同様に高速で読むことができます。進行度の保存機能もあるので電源を切っても続きから読むことができます。
とりあえずデバッグで使っている「吾輩は猫である」のテキストを読んでいますが、読む速度自体は結構早くても読めますね。ただ、古い本だと感じが旧字で見慣れなかったり、言い回しが古いので内容を理解するのが追いつかないときがあります。あらすじレベルでは頭に入ってきますが細かいニュアンスを考える時間がなく次に進んでいくので一長一短な感じはあります。
以下あまり需要なさそうな解説になります
プログラムを一応GitHubに上げてます。M5StickCPlus用にしか書いてないのでM5StickCではそのまま動かないと思います。本のデータは念のため抜いているので、別途用意が必要になります。

表示や状態管理で結構がっつりとファイル数が多くなったので今回は仕組みとポイントだけ解説していきます。
大まかな仕組み
大まかな流れとして次のような流れです。
- 元のテキストを形態素解析して文節で改行したテキストを作る
- M5StickCに加工済みテキストをSPIFFS領域にアップロードする
- M5StickC側でテキストデータを読み出し、1行ずつ表示する
テキストの加工は形態素解析で行うためM5StickCでは荷が重いので、pythonで前処理としてPCで行うようにしています。
テキストデータの加工
本を速読するのが目的なので、青空文庫からダウンロードしたテキストデータを表示用に加工するプログラムもpythonで作りました。ちなみに文を単語ごとに区切ることを分かち書きっていうんですね。

pythonで形態素解析ができるJanomeというライブラリを利用しています。これを使った理由としてはpythonでインストールが簡単でサクッと使えるためです。
形態素解析ではmecabが有名ですが、インストールが面倒そうだったのでこちらにしました。
Janomeは解析器のTokenizerをメインに前処理、後処理のフィルターを組み合わせたAnalayzerを作成してテキストを渡すだけで解析してくれます。解析で単語ごとに分かれたリストで返してくれるのでfor文などで必要な処理をします。上の例では解析した単語ごとに”/”で区切りを入れて表示します。
今回はM5StickCで表示する最大文字数を超えるか、助詞が来たら改行して表示用テキストを作っています。青空文庫から落とした「我輩は猫である」の例だとこんな感じです。
吾輩は猫である。名前はまだ無い。
↓
吾輩は
猫である
名前は
まだ無い例だとうまくいっていますが、人物名など区切れない長い単語やセリフの「」の扱いなどまだ対応しきれていないところもあるので今後考えたいところです。
また、青空文庫のテキストデータにはフリガナや底本の情報などが乗っています。本文だけで読みたいのと形態素解析が正確にできないので、前処理として正規表現などで本文だけ抜き出す作業もしています。
M5StickCにテキストアップロード
本1冊分となるとテキストデータも数百KB~1MBほどと結構なサイズになります。吾輩は猫であるを加工したテキストデータは900KBほどになりました。
これをプログラムのソースコードとして一緒に書き込むとメモリサイズが心配になったので、SPIFFS領域というデータ保存用の領域に別途書き込むことにしました。ちなみにM5StickC全体ではメモリは4MBです。そのうちアプリ領域が1.2MBらしいのでやはり足りなくなりそうですね。SPIFFSは1.5MBなので1冊分は余裕そうですが、2冊入るかは本の組み合わせ次第になりそうです。
M5StickCへのデータのアップロードはPlatformIOを使っているととても簡単です。
プロジェクトのディレクトリ直下にdataフォルダを作成し、その下にアップロードしたいファイルを配置します。今回はdata/books/以下にテキストを配置しました。
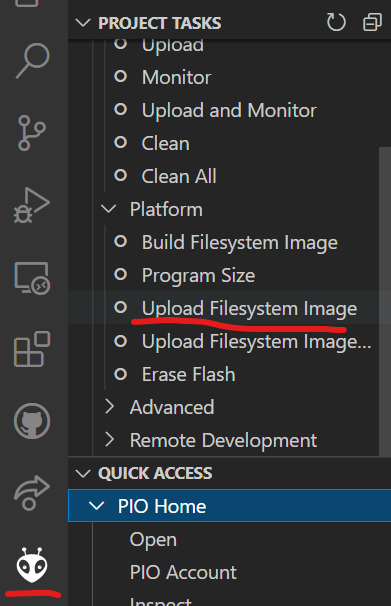
次にPlatformIOのメニューを開き、「PromiseTasks」→「Platform」→「Upload FileSyste Image」でアップロードすることができます。アップロードしたデータはプログラムの変更に関係なく保存され続け、プログラム上からアクセスすることができます。
M5StickCでの表示
ここが今回一番頑張った部分ですが、結構がっつりと表示周りや機能を書いた結果解説しきれないものになってしまいました。
そこでいくつかM5StickCならではの部分だけ紹介したいと思います。
テキストデータの読み出し
先程SPIFFS領域に保存したテキストデータの読み出し方法です。SPIFFS領域にアクセスするには、そのままなSPIFFSクラスを使用します。
SPIFFSでスタティックなインスタンスを操作します。 SPIFFS.begin()で初期化しておいて、 SPIFFS.open()でアップロード時のdataフォルダをルートとしてたパスを渡すことでファイルにアクセスできます。Fileクラスで返ってくるので扱いやすいです。
進捗状況の保存
テキストの読み進め具合を保存する機能は読んだテキストのデータ位置を記録することで実装しています。
M5Stickで簡単に情報の保存をするにはPreferencesクラスを使用します。こちらはスタティックな変数が用意されてないので自分で適当にインスタンスを作ります。
Begin()で保存先のグループ名を指定します。get〇〇()で取得、put〇〇で保存になります。〇〇の部分はIntやFloatなど保存する型ごとに分かれています。
テキストファイルを1バイトずつread()で読んでいるので、同時にカウントアップしてデータ位置を保持しています。実際は毎行で保存するのもちょっと無駄に感じたので変数で位置を保持だけしておき、テキスト選択画面に戻る際にPreferencesで保存するようにしています。
日本語フォント表示
実はM5StickCは公式ライブラリ単体では日本語フォントがないので表示できないです。(簡体字はある)
M5StickCには他にTTFフォントなどを自由に使える機能もなさそうだったのでLangShipさんのライブラリを使用させてもらいました。
https://lang-ship.com/reference/unofficial/M5StickC/UseCase/UnicodeFont/
ヘッダファイルにフォントデータごと入っているのでライブラリとして組み込むだけで使うことができます。
ですが、現状でライブラリを落として組み込むと自分の環境ではビルドエラーが出るので少し修正が必要でした。
ライブラリに含まれるefontWrapperクラスでなんでかソースとヘッダ両方に実装が書かれているのでエラーになります。自分はラッパークラスを使わなかったのでとりあえずソースのefontWrapper.cppを消して解消しました。
また、実装がすべてヘッダに書かれているので複数のソースでefont.hを直接インクルードするとリンカエラーになりました。この対策として以下のように関数を更にラップした関数を作成してそちらはソースとヘッダに分けることで回避しました。
ソース側でefontライブラリのヘッダを読むようにしています。こうすることでefontライブラリのヘッダはソースで1回しか読まれないのでヘッダの多重読み込みが防止されます。
ヘッダに実装書かれるとインクルードガードしてもそれぞれのオブジェクトコンパイルで読まれてしまうのでリンカで 多重読み込み エラーになるんですね。main.cppだけで大体書く実装なら問題ないんでしょうけどね
最後に
解説しきれないのですがM5Stickでの表示部分は結構頑張りました。以前作った魚釣りゲームのオブジェクト管理から流用してアップグレードしたので、シーン単位でオブジェクト管理や遷移ができるようになっています。UIのボタン選択なども作ったので、今後他にもリッチなアプリケーションも作っていけそうです。
ただ色々リッチにしようとするとメモリ管理がシビアになってくるので難しいですね。今回もメモリリークに悩まされたり、画像を扱うメモリ余裕がなかったりと色々難しさを体験しました。
また、本のテキスト加工をPCで前処理で分けて行っていますが新しい本を追加しようとすると手作業になるのでローカルサーバーで処理して自動化できたらいいなとも思いました。今後の挑戦目標としようと思います。
それではまた!




-
-
2年
タグ: IoT, M5Atom, プログラミング